-
Cassandra
Cassandra是什么类似HBase,Cassandra也是一个开源的分布式数据库,适用于结构化的大数据存储。
为什么使用Cassandra针对与关系型数据库的比较,可参考HBase简介一文的介绍。
与HBase的比较:
HBase
Cassandra
......
-
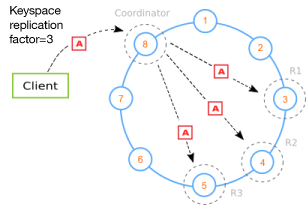
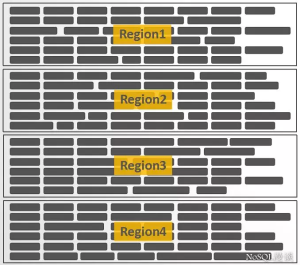
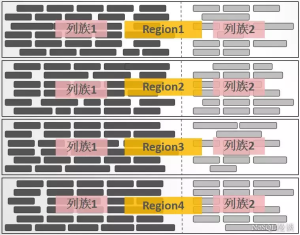
数据模型RowKey
一行记录的主键,查询的唯一条件HBase数据按字典顺序全局排序
一定要设计合理的RowKey,这直接影响HBase的读写性能。
数据表使用稀疏矩阵
RowKey
Columns
......
 共3张
共3张
-
HBase
HBase是什么
HBase是一個開源的非關係型分散式資料庫,它參考了Google的BigTable建模,實現的程式語言為 Java。它是Apache軟體基金會的Hadoop專案的一部分,執行於HDFS檔案系統之上,為 Hadoop 提供類似於BigTable 規模的服務。因此,它可以對稀疏檔案提供極高的容錯率。——维基百科
简而言之,HBase是一种基于Hadoop HDFS的列式的分布式NoSql数据库,可以用于大数据的半结构化存储与查询。
为什么使用HBase
海量数据这可能是使用常见NoSql数据库最大的优势,当数据量达到一定程度时,常用的关系型数据库的性能已经成为很明显的瓶颈,而基于Hadoop的HBase天生就适合做大数据的处理分布式由于分布式系统的架构设计,通常可以以较低的成本实现弹性扩容,避免单点故障,但也因此带来了一些问题
......
-
背景工作中遇到一个需求,同时调用了两个异步接口,这两个接口在一段时间之后会回调预设的地址,将结果返回,在回调都完成后进行下一步操作。两个接口之间没有依赖关系,有可能同时返回。
我的设计非常简单:
状态值按位表示,如右数第一位为1说明在等待异步接口A,第二位为1说明在等待异步接口B。即01表示等待A回调,10等待B,11同时等待A和B,这样在接口回调时只需要在数据库使用位操作即可确认回调已完成,如status = status ^ 2表示B接口回调完成返回的结果是Json结构保存在表中的,这是由于该表上的数据类型太多(3种不同的type共享表中其他列的数据),使用Json区分数据用途。其实当时已经考虑到了回调同时到达的情况,但没想好处理方法,因为我以为这版需求不是我做,于是埋了坑也没管,血的教训初步设计时认为将Json全量读出再将修改后的Json结构全量更新即可,很明显,这存在并发问题,于是犯难了——文本结构不像数字型,局部修改非常困难如果改为串行调用两个接口,实现起来会非常麻烦和啰嗦,这是最后手段
今天看到数据导出工单里有一条奇怪的SQL语句:
SELECT json_extract(detail,"$.width") ... FROM ... WHERE ...
第一眼并没有很在意,但是鬼使神差我又回过头来看了一下这条记录,从语义上看似乎在单独读取Json结构中的数据,但是真的有这种操作吗?还是说这是自定义函数?这会不会是解决我燃眉之急的曙光?带着将信将疑的态度打开Google,没想到就此打开了新世界的大门。
......
-
Jedis简介Jedis是Redis的Java客户端实现,封装了对Redis的通信和命令处理等。Jedis提供了资源池,可以很方便地实现对Redis的API调用。
Jedis集成目标之前是通过组内对Jedis封装的Spring Bean来获取和使用Jedis的,现在希望自行实现类似功能,设计目标如下:
封装为Spring FactoryBean集成目前自行实现的基于ZooKeeper的配置中心组件获取单个连接,避免每次调用需要从资源池中获取一个连接的额外操作(其实还有归还操作)实现在服务启动依赖注入后配置变更仍然能生效
思路具体思路就是针对设计目标而定的:
实现FactoryBean接入Config组件DCL单例生成资源池JedisPool,并通过动态代理提供Jedis连接,连接从JedisPool中获取配置变更后使用新的JedisPool替换旧的
具体实现由于需求比较基础,还没有太多应用场景,实现也没考虑太复杂。整体逻辑不到50行,可以在我的GitHub上大致看一下。后续使用可以直接使用Spring将Bean注入。
......
-
背景maven deploy的过程中Archiva一直响应没有权限,于是想起来Archiva系统有个比较怪的点——默认是需要定期修改密码的。一旦之前设置的密码过期,就必须通过“忘记密码”流程修改,而这个流程需要发送邮件,不过可能这个邮件发送有什么问题,一直收不到。于是乎就必须走重新创建用户的流程,即删除Archiva的用户信息目录后重启。我的用户目录在/usr/local/data/databases/users。查阅资料后,发现可以在Archiva的WebUI中User Runtime Configuration-Properties第三页-security.policy.password.expiration.enabled选项设置为false关闭密码过期策略。
惨痛的掉坑过程原以为关闭过期策略就万事大吉,没想到后续的这一系列操作直接把CI/CD流程整瘫痪了:
删除用户目录并重启,在WebUI关闭了密码过期策略部署博客服务后服务启动失败,仅瞟了一眼日志就误以为内存不够用了ps.这里特别说明一下,服务器内存比较小(穷),在扩容内存之前是经常不够用的,于是惯性思维,认为确实内存不够用了。而后来定位到真正的原因是服务器maven package过程中jar未更新。把Archiva所使用的Tomcat关闭,释放内存资源服务仍然启动失败,发现原来是jar有问题,于是尝试修复jar中的问题(当然,实际上是jar未更新)需要部署jar,因此又启动Archiva,这时Archiva启动不了,报错
至此,整个状态是:博客服务由于依赖问题无法启动;Archiva服务无法启动;Jenkins正常但由于Archiva瘫痪无法打包发布。
Archiva报错内容核心错误日志:
... # 服务无法启动
......
-
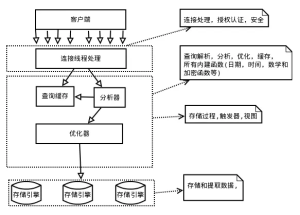
架构
MySQL架构图
MySQL的架构分为三层。
第一层只负责提供服务,包括链接处理、授权认证、安全等,做一些必要的检查、适配工作,类似Web应用的Controller层。
第二层包含了大多数MySQL的核心功能,包含查询解析、分析、优化、缓存等,以及一些跨存储引擎的功能,类似Web应用的Service层。
第三层包含多种存储引擎,每种引擎有自身的特性,但最终提供统一的底层API与上层通信,屏蔽了底层存储引擎的差异,类似Web应用的Dao层。
......
-
MySql
MySql是什么作为最流行的关系型数据库,不用我说明了。
MySQL原本是一个开放源码的关系数据库管理系统。MySQL在过去由于性能高、成本低、可靠性好,已经成为最流行的开源数据库,因此被广泛地应用在Internet上的中小型网站中。随着MySQL的不断成熟,它也逐渐用于更多大规模网站和应用,比如维基百科、Google和Facebook等网站。非常流行的开源软件组合LAMP中的“M”指的就是MySQL。——维基百科
为什么用MySql原因有三——开源、可靠、性能好。个人用户或者中小企业的数据库基本用MySql就够了。
MySql的知名客户
官方网站https://www.mysql.com/cn/
......

 共3张
共3张
-
Spring任务说明Spring任务分为异步任务和定时(周期)任务。
异步任务时表示Spring分配另一个线程执行这个任务定时任务表示任务在预设的时间在由Spring分配线程执行,周期任务可以转化为定时任务,这里看做一种
在Spring中,异步和定时任务由org.springframework.core.task.TaskExecutor接口的实现类执行,常见的TaskExecutor如下:
SimpleAsyncTaskExecutor 每次调度的时候都会启用一个新的线程执行任务。ConcurrentTaskExecutor 接收一个java.util.concurrent.Executor对象作为参数,然后执行任务的时候会使用内部的java.util.concurrent.Executor调度。ThreadPoolTaskExecutor TaskExecutor的线程池实现,类似于JDK的ThreadPoolExecutor,可以进行线程池的大小定义等。ThreadPoolTaskScheduler 可以定时执行任务的实现,同时实现了TaskExecutor接口和TaskScheduler接口。
Spring任务的配置xml配置
<!-- 扫描注解 -->
......
-
Spring支持的事务Spring提供两种事务管理方式,分为编程式和声明式。
编程式:通过编码的方式手动启用、提交或回滚事务,粒度更细,但更麻烦。声明式:通过在方法或类或接口上添加注解进行包装,无侵入地实现事务,更方便,但粒度更大。
需要注意的是,使用的数据库需要支持事务,否则事务将不起作用。如MySql的MyIsam引擎就不支持事务。
Spring事务的配置添加依赖
<dependency>
<groupId>org.springframework</groupId>
......
-
Spring
什么是Spring
Spring框架是 Java 平台的一个开源的全栈(Full-stack)应用程序框架和控制反转容器实现,一般被直接称为 Spring。该框架的一些核心功能理论上可用于任何 Java 应用,但 Spring 还为基于Java企业版平台构建的 Web 应用提供了大量的拓展支持。虽然 Spring 没有直接实现任何的编程模型,但它已经在 Java 社区中广为流行,基本上完全代替了企业级JavaBeans(EJB)模型。——维基百科
作为Java后端程序员,甚至扩展到Java程序员,应该没有人没听说过Spring Framework,我想应该不用过多介绍了。Spring作为一个框架,完成了大量基础工作,抽象了大量可复用的逻辑,让开发工作可以将注意力集中在业务中,同时帮助业务模块解耦。现在Spring已经集成了包括MVC、Redis、ElasticSearch、Cloud、事务等多种常用模块,再加上Spring Boot这种“约定大于配置”的开发模式,对于Java后端程序员来说可以使用Spring全家桶用及其迅速的方式完成业务逻辑的开发。可以非常负责任地说,现阶段Apache基金会的开源项目和Spring的一系列框架已经成为了Java社区两个最重要的支柱。
为什么用Spring怎么使用SpringSpring官网https://spring.io/
参考资料
-
发布订阅Redis的发布订阅功能可以实现一个简单的消息队列。Redis客户端可以通过命令SUBSCRIBE、PSUBSCRIBE等命令实现订阅频道,成为该消息队列的消费者,在Redis中对该频道建立或添加一个链表保存该客户端节点。其中SUBSCRIBE是直接添加客户端到对应的频道链表中,而PSUBSCRIBE是添加到pattern链表中,在产生消息时通过正则匹配确认是否是消费者。当订阅该频道的客户端执行PUBLISH命令,会在频道中产生消息,发送给所有订阅该频道的消费者。
事务MULTI命令会启用该客户端的事务队列,后续该客户端的合法命令都会入队列但不执行。当执行EXEC命令时,服务器执行该客户端队列的所有已入队命令,中途不会切换处理其他客户端命令,保证事务的原子性。事务中任何一个命令执行失败,不会影响其前后命令的执行,不会引起事务回滚。如果客户端有执行WATCH命令监视一些key,那么在EXEC命令执行前会检查其监视的key在WATCH期间是否被其他客户端修改过。一旦任何key被修改过,可认为事务不再安全,整个事务将不会执行。Redis事务的ACID:
原子性:命令执行失败不会引起事务中断,其他命令仍然会执行。事务的前置条件有问题,那么事务不会执行。要么全执行,要么全不执行一致性:Redis在入队、执行时都检查了命令,且故障时可通过RDB或AOF文件恢复,数据库中不会保存错误、不合法的数据隔离性:Redis是单线程处理事件的,在事务执行期间不会中断事务去执行其他客户端的命令,保证事务之间是隔离的耐久性:Redis基本没提供相应的保证
为什么 Redis 不支持回滚(roll back)如果你有使用关系式数据库的经验, 那么 “Redis 在事务失败时不进行回滚,而是继续执行余下的命令”这种做法可能会让你觉得有点奇怪。
以下是这种做法的优点:
Redis 命令只会因为错误的语法而失败(并且这些问题不能在入队时发现),或是命令用在了错误类型的键上面:这也就是说,从实用性的角度来说,失败的命令是由编程错误造成的,而这些错误应该在开发的过程中被发现,而不应该出现在生产环境中。因为不需要对回滚进行支持,所以 Redis 的内部可以保持简单且快速。
......
-
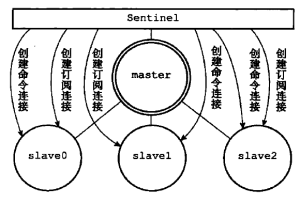
主从复制模式通过简单的命令可以设置几个Redis服务器之间的主从关系。主服务器保存了一个复制积压缓冲区和复制偏移量,并通过心跳检测机制来发现主从服务器断连或者命令丢失的问题。当出现主从数据不一致时,主服务器可以根据缓冲区和偏移量重发丢失的命令。
复制积压缓冲区,实际上就是一个队列,按字节将所有需要同步的命令一一保存复制偏移量,保存接收了多少字节命令,主从偏移量不一致说明数据不同步
哨兵(Sentinel)哨兵是一个特殊的Redis服务器,不进行数据存储服务,只负责保证Redis主从模式的高可用性。哨兵监测并记录每个主从服务器的工作状态,并对服务器进行故障转移,尤其是对主服务器故障进行特殊处理。
哨兵与所有主从服务器都建立“命令连接”和“订阅连接”订阅连接用来发现其他的哨兵哨兵与其他哨兵之间建立命令连接,不需要建立订阅连接
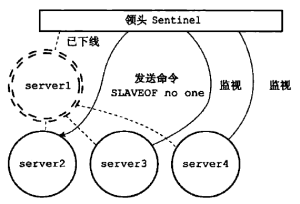
Leader Sentinel选举哨兵也可以采用主从模式配置,主服务器是通过分布式一致性协商算法——Raft算法选举产生的。Raft动画详见参考资料,浅显易懂。Leader选举是采用先占坑先得的选举方式,每次选举时直接向其他哨兵申请成为该哨兵唯一的局部leader,成为半数以上哨兵局部leader的哨兵将会成为新leader。如果没有选出leader,则进行下一轮选举。Leader选举实现的核心思想是谁最先发现主服务器下线,综合其与其他哨兵的传输延迟低,谁就最可能成为下一任主服务器。
主从模式故障转移监测到主服务器故障时,哨兵询问其他监视这个服务器的其他哨兵,并收集下线投票,确认其是否下线。当确认主服务器下线后,哨兵从这个主服务器的从服务器中挑选一个成为新的主服务器。筛选的核心思想是服务正常,最近有通信,数据较新。筛选条件:
......
 共8张
共8张
-
背景每日需要在MySql中记录一些日志数据,由于数据量较大,单表查询效率肯定受影响,且明确可以按照日期拆分,因此每日建表。同时由于数据量过大,又忘了定期清理,后期发现磁盘空间不足,需要批量删除表。
模板创建表思路创建一张空表作为模板,之后每天根据这个模板克隆一个新表,后缀为日期。避免定期任务出现重复建表,使用CREATE IF NOT EXISTS。
语句使用Mybatis注解的形式:
CREATE TABLE IF NOT EXISTS prefix_${day} LIKE prefix
# 也可以使用 'CREATE TABLE AS' 克隆表和数据,但是我们这里不需要数据
# CREATE TABLE prefix_${day} AS SELECT * FROM prefix
......
-
键空间Redis的数据库包含了键空间结构,可以理解为JVM保存了所有对象的引用。键空间是一个字典结构dict,包含了所有key的引用,每个key有指针指向对应的value,value可以是string、list、hash等类型的对象。
过期数据库包含expires字典,保存了所有key的过期时间。Redis采用惰性删除+定期删除处理过期的key:
惰性删除 在任何命令执行前确认是否已过期,如果过期了就先把key(和value)删除定期删除 定期随机从expires字典中抽取一定数量key检查是否过期,并删除过期keyexpire、expireat等命令最终都会被转为pexpireat命令。
持久化RDB持久化本质上就是将内存中的Redis数据dump出来一份文件,一般定期执行,恢复时可能会丢一些数据。AOF持久化本质上是命令重放,但也不是实时写入,如果服务挂了会丢失写缓冲区里的命令,写入频率比RDB高,丢失的数据相对很少。还可以通过AOF重写,直接根据数据库内容“生成”命令,压缩命令数量(如将多条SADD命令合并,或将数据的写入、删除命令抵消)。也就是说,不是持久化命令,而是持久化状态。
RDB 的优点
RDB 是一个非常紧凑(compact)的文件,它保存了 Redis 在某个时间点上的数据集。 这种文件非常适合用于进行备份: 比如说,你可以在最近的 24 小时内,每小时备份一次 RDB 文件,并且在每个月的每一天,也备份一个 RDB 文件。 这样的话,即使遇上问题,也可以随时将数据集还原到不同的版本。RDB 非常适用于灾难恢复(disaster recovery):它只有一个文件,并且内容都非常紧凑,可以(在加密后)将它传送到别的数据中心,或者亚马逊 S3 中。RDB 可以最大化 Redis 的性能:父进程在保存 RDB 文件时唯一要做的就是 fork 出一个子进程,然后这个子进程就会处理接下来的所有保存工作,父进程无须执行任何磁盘 I/O 操作。RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快。
......
-
基础字符串结构SDS我们知道,Redis数据结构中最基础的内容是字符串,而字符串的基础结构是字符数组。由于Redis中可以被修改的字符串通常使用一种名为简单动态字符串(simple dynamic string, SDS)的结构。SDS的结构
struct sdshdr {
// 已使用长度
int len;
// 未使用长度
int free;
......
-
用途放在tomcat所在目录下,快速dump出当前系统、java、tomcat的各种状态。
原理就是利用jstack等jvm自带命令和/usr/bin/free等系统自带命令,打印输出,非常简单。虽然原理简单,但一键把有的没的都给你dump了,也省事。
代码注意放在tomcat根目录,目的是获取对应的java进程id,其实自己设置也可以。注意修改JAVA_HOME等参数。
#!/bin/bash
JAVA_HOME=/data/wenwen/jdk1.8/jdk1.8.0_172
#dump文件输出目录
......
-
背景根据服务器的Access日志,跑出指定id的数据在不同时间段内被访问的次数,以小时为单位。由于用了很多shell脚本常用的代码,就贴出来,哪天忘了来翻一翻。
思路问题:
原日志gzip压缩过原日志量实在过大,直接暴力统计恐怕吃不消不要产生过大的中间文件最好可选天数结果最好能方便转成Excel文件格式
流程:
输入日期参数gzip解压原日志通过awk只取原日志关键的几个列,包括时间、url只保留命中名单的qid数据,写入临时文件按小时统计行数输出结果删除临时文件
几个注意的点权限写完脚本记得设置执行权限,通常chmod 755,也就是-rwxr-xr-x
......
-
背景遇到一个任务需要写脚本读特定发件人发送的邮件内容。读邮件实现方式很多,但大多数不现实:
在服务器上搭个邮件服务——太麻烦了,杀鸡用牛刀找到邮件客户端保存的邮件数据直接读取——显然客户端都有加密机制,麻烦自己实现邮件客户端去服务器取——各种权限机制估计很难应付写个脚本通过Linux命令行登录邮件服务器——这种方式比较简单
策略筛选邮件反正公司电脑长期不关,使用的邮件客户端是Foxmail,带有过滤器功能,那么新建过滤器,当收到这个人发的邮件时自动转发给单独创建的某邮箱账号,保证这个账号只会收到特定的内容(少量垃圾邮件也行,总之不能影响自己的邮箱使用)。
取邮件内容服务器上部署一个简易服务,定期通过Linux命令行登录取到邮件内容。
分析内容后续处理。
流程以pop3.163.com为例,但具体邮件服务器需要自行确认。
......
-
Linux的企鹅Tux,比腾讯企鹅年纪大
Linux是什么
简单地说,Linux是一套免费使用和自由传播的类Unix操作系统,它主要用于基于Intel x86系列CPU的计算机上。这个系统是由世界各地的成千上万的程序员设计和实现的。其目的是建立不受任何商品化软件的版权制约的、全世界都能自由使用的 Unix兼容产品。——搜狗百科
当前的主流操作系统基本分两种:
Windows图形化界面用起来方便,用户入门简单,但由于微软极强的控制欲和过度的对用户进行傻瓜式保护,很多非常简单的功能却无法实现用户自定义,或者说可能比起类Unix系统的学习成本更高。Windows也有命令行,但是功能和通用性有限。类Unix系统包括苹果公司的图形化用户界面(Graphical User Interface,GUI)操作系统MacOS;服务器常用的命令行操作系统CentOS(也可以使用 GUI,但服务器不需要)。
为什么用Linux一般来说服务器使用Linux内核系统(以下简称Linux系统)较多,因为Linux系统运行稳定消耗资源少(不容易崩溃),对于大多数开源应用兼容性非常好(绝大多数开源软件就是为Linux系统量身打造的),这些都是原因之一。最大的原因是Linux是自由的:
......
-
Redis
Redis是什么
redis是一个key-value存储系统。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(有序集合)和hash(哈希类型)。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排序。与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。——搜狗百科
日常工作(不包括优化、策略选择、异常排查等)可以不用过于深入了解,只需要把Redis理解为:一个高性能、适用于多种数据类型但容量相对较小的存储系统;数据保存在内存中,能很好地支持数据过期;单进程,所有命令都是原子操作,可以搭建分布式集群;支持主从同步,可保存二进制数据。
官方网站https://redis.io/
Redis的适用场景Redis最大的特点就是高性能、容量相对小、原生支持失效,因此最常用的场景是用于缓存,在进行读写频繁或写少读多的操作时加在核心存储之前,如:
......
-
Zookeeper权限分类Zookeeper ACL(Access Control List)一共分为5种权限:
权限
ACL简写
描述
ADMIN
a
......
-
遇到过的问题重复注册
Curator可以通过client.getData()usingWatcher(curatorWatcher).forPath(path)来实现节点事件监控,但watcher只生效一次,每次事件触发后,该watcher就失效了。需要持续监控的节点事件需要重复注册watcher。
版本问题
某些Zookeeper对应特定版本的Curator,否则启动会报错。
Zookeeper3.5.x需要使用Curator4.x版本Zookeeper3.4.x需要使用Curator2.x版本(不知道Curator3.x版本是什么情况,很久没有更新了)
Curator版本列表
......
-
Curator介绍
Apache Curator is a Java/JVM client library for Apache ZooKeeper, a distributed coordination service. It includes a highlevel API framework and utilities to make using Apache ZooKeeper much easier and more reliable. It also includes recipes for common use cases and extensions such as service discovery and a Java 8 asynchronous DSL.Curator是Zookeeper的客户端库,包含了高级JavaAPI框架和工具,让使用Zookeeper变得更简单和可靠。也包含了一些常见的和扩展的用例,比如服务发现和Java8的异步DSL(domain-specific language,特定语言)。——来自Curator官网
简而言之就是一个封装更完善的API库。
Curator官网http://curator.apache.org/
Curator常用Maven依赖
GroupID
......
-
和Apache旗下的其他项目一样,部署非常简单。部署流程
访问Zookeeper的releases页面https://zookeeper.apache.org/releases.html挑选合适的镜像,下载Zookeeper的压缩包解压缩修改配置运行
详细指令
# 下载
wget http://apache.mirrors.tds.net/zookeeper/zookeeper-3.4.13/zookeeper-3.4.13.tar.gz
# 解压
......
-
ZooKeeper
Zookeeper是什么
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。——搜狗百科
Zookeeper最核心的定义:分布式应用程序协调服务。Zookeeper最核心的功能:为分布式应用提供节点管理、注册和同步的功能。
为什么使用Zookeeper在实现配置中心的过程中,最重要的特性:近实时同步数据。而这点可直接依赖高效稳定的Zookeeper服务,基于其注册和通知机制提供。
Zookeeper官网https://zookeeper.apache.org/
......
-
Maven的核心配置文件一般位于%M2_HOME%/conf/settings.xml,涉及到本地仓库配置、远程仓库配置、镜像配置及一些其他参数的配置。
常用配置 <!-- 本地仓库path,默认位于%USER_HOME%/.m2/repository -->
<localRepository>repositoryPath</localRepository>
<!-- 镜像,可用于远程仓库连接不上(比如内网环境)或内容在远程仓库中找不到时使用,我这推荐阿里云的镜像 -->
<mirrors>
<mirror>
......
-
packagingmaven编译打包结果,war用于web应用部署,jar用于依赖部署
<groupId>com.xxx</groupId>
<artifactId>xxx</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>war</packaging>
buildweb应用打包时可选择编译参数
......
-
Git集成
12
2018-10-15 20:27:59
Git官网https://git-scm.com/
Git客户端安装在我们的开发机上直接下载、安装客户端即可。
Git集成IntelliJ Idea在Idea中选择选项:File——Settings——Version Control——Git选择git.exe位置即可完成集成,剩下的事建议交给GitHub客户端。
Git仓库GitHub介绍
GitHub 是一个面向开源及私有 软件项目的托管平台,因为只支持 Git 作为唯一的版本库格式进行托管,故名 GitHub。作为开源代码库以及版本控制系统,Github拥有超过900万开发者用户。随着越来越多的应用程序转移到了云上,Github已经成为了管理软件开发以及发现已有代码的首选方法。——搜狗百科
发展了这么多年,看起来Git已经快沦为GitHub组件了。
......
-
集成Maven部署服务端增加Archiva用户在Archiva的webUI的Manage选项增加用户,该用户需要有Repository Manager权限客户端修改Maven配置文件settings.xml仅列出了文件的部分内容
<servers>
<server>
<id>archiva.internal</id>
<username>前一步设置的用户名</username>
<password>前一步设置的密码</password>
......
-
部署Archiva官网说得很详细,这里简述一下2.2.3版本的安装过程,更多内容参考官方说明文档。https://archiva.apache.org/docs/2.2.3/quick-start.html
#下载
wget http://apache.claz.org/archiva/2.2.3/binaries/apache-archiva-2.2.3-bin.zip
#解压
unzip apache-archiva-2.2.3-bin.zip
#增加软链
......
-
Archiva
Archiva是什么Archiva是由Apache提供的Maven私人服务器,用于为Maven构建工程时提供仓库服务。
Archiva的同类产品比较出名的是Sonatype Nexus,GitHub有人给出了几大类Maven服务器的主要差别。https://binary-repositories-comparison.github.io/在用户角度来看,其实差不了太多,不过我对Apache天生有好感,Archiva配置也是非常简单。而且很多公司已经在使用Nexus了,Archiva文档较少,那么就来试试水。
为什么使用Archiva应该说为什么使用Maven私服。主要原因是这几点:
生产环境大多数工程依赖的jar包是一样的,甚至版本基本也一样,私服可以很好地起到缓存作用,减少带宽消耗,加速依赖下载过程生产环境可能是内网环境,发布系统Maven打包时无法连接Maven中央仓库可以控制仓库中的jar包版本,从而控制代码依赖的版本可以上传自己的工具jar包,利于解耦和代码复用
Archiva官网https://archiva.apache.org/index.cgi
......
-
安装
官网下载、安装TortoiseSVN,安装时要选择命令行插件,否则无法集成IDEA
集成
在IntelliJ IDEA中打开选项File——Settings——Version Control——Subversion勾选Use command line client,路径为TortoiseSVN\bin\svn.exe在IDEA中打开选项VCS,添加版本控制工具为subversion
IDEA使用
导入Import:IDEA选项VCS——Import into Version Control——Import into Subversion提交Commit/更新Update:修改后选择IDEA面板小箭头
......
-
安装依赖
安装httpdyum -y install httpd
配置httpdvi /etc/httpd/conf/httpd.conf
# 可以设置端口
启动httpd# 启动后通过浏览器访问ip:port
service httpd start
......
-
配置文件目录Nginx安装目录如/usr/local/nginx配置文件位于conf目录下,/usr/local/nginx/conf
入门配置Nginx的主要配置文件是nginx.conf
# 工作进程数,推荐跟cpu内核数一致
worker_processes 1;
# 并发链接数
worker_connections 1024;
......
-
安装依赖pcre官网:http://www.pcre.org/
wget http://downloads.sourceforge.net/project/pcre/pcre/x.xx/pcre-x.xx.tar.gz // 下载最新版本
tar zxvf pcre-x.xx.tar.gz // 解压
cd pcre-x.xx
./configure // 检查配置,生成makefile
make && make install // 编译 安装
......
-
Nginx
官方网站https://nginx.org/en/
-
环境Linux(CentOS)系统tcl工具(否则后期make test时报错:You need tcl 8.5 or newer in order to run the Redis test),tcl安装过程:
wget http://downloads.sourceforge.net/tcl/tcl8.6.3-src.tar.gz // 下载,注意版本
tar -zxvf tcl8.6.3-src.tar.gz // 解压
cd tcl8.6.3/unix/
./configure // 检查配置
make && make install // 编译、安装,可以切换目录
......